
I detailed in a recent post how I got a working WordPress container setup, complete with database and PHP engine. I saved the bit about how to redirect traffic to the container (and apply encryption to the outbound connections) because I knew it was going to be just as much work as getting the setup running. Also I needed to first get up to speed on HTTP headers in general and how to inspect them specifically.
This post is not a how-to any more than it’s a how-not-to. I wanted to detail as much the attempts that did not work as the final one that did because the former were just as illuminating as the latter.
The challenge here is mostly to do with how to pass on requests from a reverse proxy running on the host to an application running in a container, in this case WordPress. The basic passing requests on through the proxy is accomplished fairly easily by using Nginx’s proxy_pass directive.
No, the tricky part is that running in a container changes a number of variables for the application: Hostnames, ports, IP addresses, subnets, protocols etc. This means that http requests need to be modified by Nginx’s proxy_set_header if the application is to produce correct URLs and not get lost in a mismash of mixed internal and external references.
This effort is one part making-it-work to three parts learning experience. There’s a lot of copy-pasta configs out there that I could just throw at the wall if ‘making it work’ was all I wanted. For these and other reasons I will follow these restrictions
- No 301 hacks: When using a reverse proxy to encrypt unencrypted sources it is very common to add a virtual server (on the proxy) listening to port 80 and answering with a status 301 (permanent redirect). Thus the client making an http request is told to try again, only this time using https. This is a reasonable thing to do when people enter your site name straight in the browser. Most browsers still work on http by default, not https, and if you’re not listening on port 80, the user finds nothing. However, it feels like a crutch when you’re setting things up because you’re also catching all the port 80/http requests that your own application is generating. Rather than ‘fixing’ those requests in the reverse proxy I want to focus on fixing them at the source: In the application generating URLs and the 301 fix just makes it harder to find those source errors. It also has the downside of generating more needless traffic because every request is now two requests: First an http one and then a corrected https one.
- No header stuffing: StackOverflow configs being passed around tend to go with a better safe than sorry approach to adding headers to requests. While needless headers may do no harm they do obscure what is actually working.
Using what I learned in the tshark post I started out by just listening to the bridge of the wp_net docker network to see what I can learn.
The first thing I notice is that host nginx (reverse proxy) is forwarding the requests as http/1.0 whereas docker nginx (web server) is responding using http/1.1.
Hypertext Transfer Protocol
GET / HTTP/1.0\r\n
[Expert Info (Chat/Sequence): GET / HTTP/1.0\r\n]
[GET / HTTP/1.0\r\n]
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
[Expert Info (Chat/Sequence): HTTP/1.1 200 OK\r\n]
[HTTP/1.1 200 OK\r\n]In order to keep the entire connection on http/1.1 I use the proxy_http_version directive (in the http context though it can be set a lower levels as well) on the host configuration:
proxy_http_version 1.1;With that out of the way it was time to actually try to get requests through to the containerized WordPress instance.
Attempt zero
To keep it safe and simple I start off by directing traffic to a container serving up a static html page rather than my actual WordPress container. The Nginx default page does not need to be self aware in the same way that an application does and so should be more tolerant of bad and misleading requests. I start up a container aimed solely at presenting the Welcome to Nginx default page. Here’s it’s server block:
server {
listen 80;
server_name test.mydomain.net;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}All that is required on the host for this to work is the proxy_pass directive:
server {
listen 80;
server_name test.mydomain.net;
location / {
proxy_pass http://127.0.0.1:5080;
}
}The point here is that with a static page http headers are less likely to muck things up. Even when the headers are a bit off things work out. Take this host header in the request as it appears inside the container, for example:
Host: 127.0.0.1:5080\r\n The browser’s request was for Host: test.mydomain.net but host Nginx has automatically reset it.
By default, NGINX redefines two header fields in proxied requests, “Host” and “Connection”, and eliminates the header fields whose values are empty strings. “Host” is set to the
NGINX Docs: Passing Request Headers$proxy_hostvariable, and “Connection” is set toclose.
The value of the $proxy_host variable – http://127.0.0.1:5080, the port on the host machine where the container’s port 80 is forwarded to – is substituted for the browser request’s value of test.mydomain.net. But my server block inside the container is set to respond to calls for the host test.mydomain.net, not 127.0.0.1? Yes, but there are no better matches – in fact, there are no other matches – than the single server block I have. So Nginx is forced to use it though the host name match is terrible. When all other options are exhausted:
If no regular expression match is found, Nginx then selects the default server block for that IP address and port.
Justin Ellingwood: Understanding Nginx Server and Location Block Selection Algorithms
And since there is no application that works with the header’s values we don’t get any weird responses back. The container returns a static html document because that’s all that container Nginx is set to do. This still holds when I apply encryption to the outside connection on the host:
server {
listen 443 ssl;
server_name test.mydomain.net;
ssl_certificate /etc/ssl/private/test.mydomain.net/fullchain.pem;
ssl_certificate_key /etc/ssl/private/test.mydomain.net/privkey.pem;
include conf.d/ssl.conf;
location / {
proxy_pass http://127.0.0.1:5080;
}
}The request passed on to the container is unchanged. The change of protocols only affects the outside connection and we are currently opting not to explicitly inform docker Nginx of that change.
First attempt
Naively switching to my proper WordPress setup rather than the static Nginx page results in… well success of a sort. I get an unadorned WordPress setup page inviting me to choose an install language. And by unadorned I mean that clearly images and stylesheets took a wrong turn and went missing.
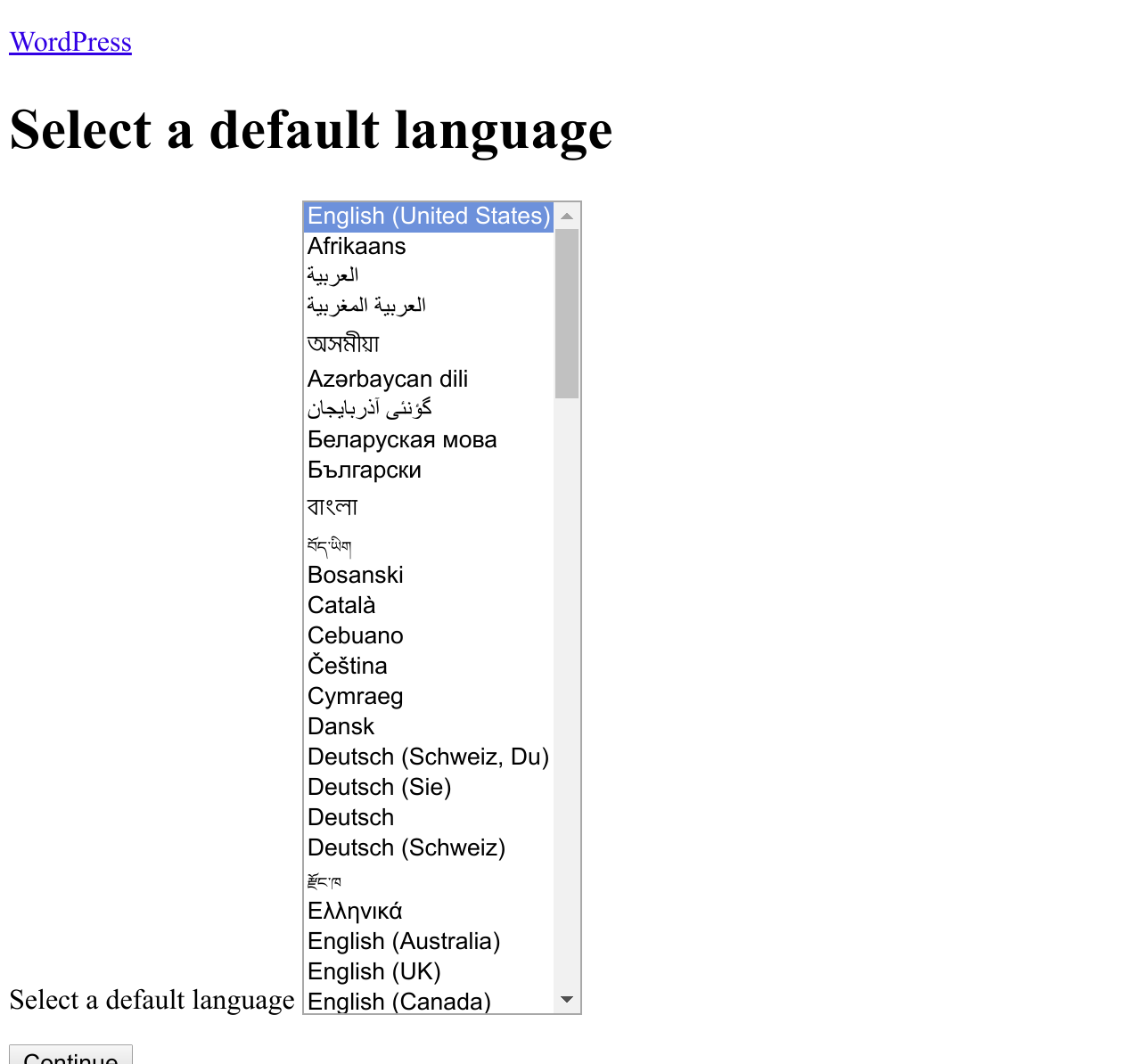
In hindsight this is not that surprising, really. Looking at the source code of the page the problem is obvious:
<link rel='stylesheet' id='buttons-css' href='http://127.0.0.1:5080/wp-includes/css/buttons.min.css?ver=4.9.8' type='text/css' media='all' />
<link rel='stylesheet' id='install-css' href='http://127.0.0.1:5080/wp-admin/css/install.min.css?ver=4.9.8' type='text/css' media='all' />I am however able to complete the installation successfully but get caught by the login mechanism which keeps redirecting me to http://127.0.0.1:5080.
Second attempt
It’s clear that I need to – and did – address the issue of changing the request headers, around this point. If I simply add some to my WordPress install, I get results… of a kind:
location / {
proxy_pass http://127.0.0.1:5080;
proxy_set_header X-Forwarded-Host $http_host;
proxy_set_header X-Forwarded-Port 80;
}$http_host is an Nginx variable that equates to the original host asked for by the client, i.e. the browser. If the application makes use of the X-Forwarded-Host header it can tell what host the client is expecting to answer.
With this I get access to a very basic looking site for the same reason as before, namely because the addresses used in the page are all local. Enough functions are using the X-Forwarded-Host/X-Forwarded-Port headers to enable some navigation, though most links on the page point to the local ip:port combination. If I add setting the HOST header to http_host, I don’t get through at all because I get redirected to test.mydomain.net:5080.
At this point I start suspecting that setting up WordPress in one context, and then slapping on some more correct headers may be a source of confusion. I go into the database and look at the wp_options table which is where WordPress stores general settings. The values of siteurl and home do indicate that this approach has been problematic.
| 1 | siteurl | http://127.0.0.1:5080 | yes |
| 2 | home | http://127.0.0.1:5080 | yes |Clearly the install process is crucial here. WordPress presumably scans the requests coming in and uses the information therein to form it’s idea of it’s own identity in it’s siteurl and home settings. This then provides the basis of future URL generation. I’m hazy on the details but it seems that when the settings and visiting requests’ host headers clash, confusion ensues.
Third attempt
Resetting the database and re-running the install process with the forwarded HOST and X-forwarded-* headers clears it up.
This is when I got cocky and searched for a quickfix for moving WordPress installs to https and came up with the brilliant plan to just change the two settings above – siteurl and home – by way of the WordPress General Settings page. Obviously, the site fails after hitting save because I’m still trying to access it on http but, I figured, that would work itself out once I changed the host Nginx configuration to use https, SSL, port 443 etc.
The result was once again a very mixed bag with few to no images showing up because they or the css putting them in were located using http and not https. This is also an obvious example of the dangers of using 301 redirects to ‘autocorrect’ non-encrypted http requests.
The most notable error apart from the missing images was the endless redirecting on the wp-login.php page. Essentially WordPress answered all request to login by telling the client to redo the request – using the same location as before (http status code 302). Needless to say the browser balks after a dozen of these or so.
What exactly is going on here I cannot tell but it was clear that the approach was misguided. Similarly to the switch from local addresses to global, a change in protocol is not something I could just add on afterwards. As appealing as the thought of adding complexity layer by layer was, I would have to figure out a way to get WordPress to use https from the get-go.
Fourth attempt
The way to do that, it turned out, was to add the option to WordPress’ configuration. In a ‘normal’ or non-proxied context I’m guessing WordPress will be able to tell what protocol is being used and adapt the URLs accordingly (http or https) In my setup the original https is hidden from the container so it just defaults to generating http-URLs.
I proceeded to add the following block to wp-config.php:
define('FORCE_SSL_ADMIN', true);
// in some setups HTTP_X_FORWARDED_PROTO might contain
// a comma-separated list e.g. http,https
// so check for https existence
if (strpos($_SERVER['HTTP_X_FORWARDED_PROTO'], 'https') !== false)
$_SERVER['HTTPS']='on';So: If ‘https’ is found somewhere in the HTTP_X_FORWARDED_PROTO part of the $_SERVER array variable, set the HTTPS part of same variable to ‘on’, yes? Also, I am now only allowed access to the admin section over an encrypted connection. As this makes use of the X-Forwarded-Proto header, I add it to the mix on the reverse proxy, setting it to the Nginx variable $scheme which should always evaluate to ‘https’ in the current setup.
Now, things look great at first. The site works, all ressources load over https, but attempts to login results in http status 403 responses: You are not allowed to access this page.
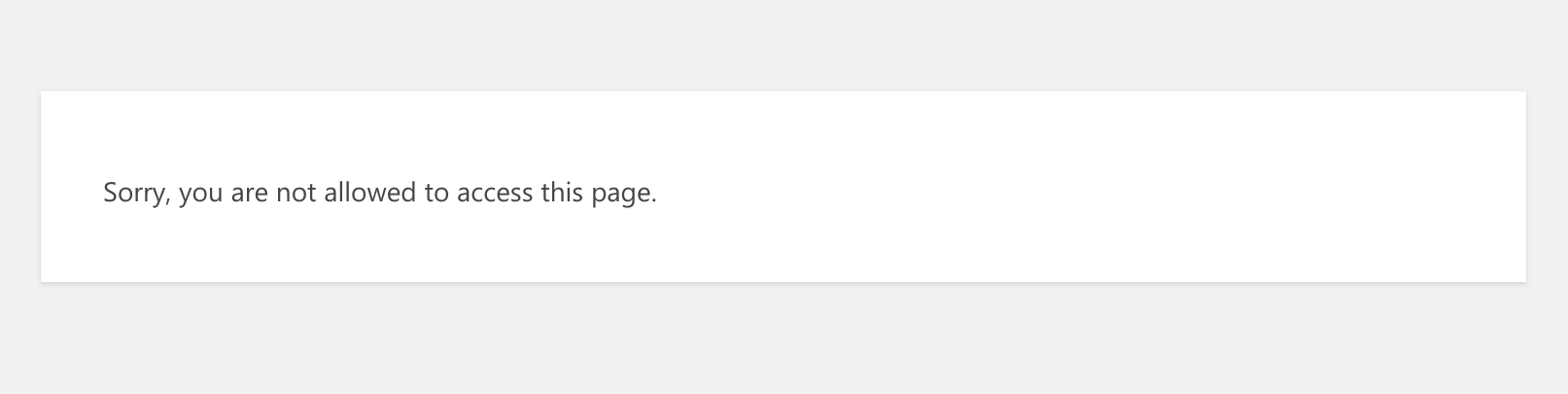
Fifth attempt
This one only requires a quick internet search to solve. It turns out that the SSL block should come before the block referencing wp-settings.php:
/** Sets up WordPress vars and included files. */
require_once(ABSPATH . 'wp-settings.php');Moving it up to the head of the file solved the issue. Now the whole site is useable in https, all ressources load and I’m allowed to login and administrate. A quick sniff with tshark shows no obviously bad requests.
X-Forwarded-for
I have avoided the X-Forwarded-For header so far because it is not really relevant to the main purpose of this little venture. This header tells the application where the original request comes from. The application does not need to know that to fulfill the request because ultimately, sending the response back to the browser is the job of the reverse proxy.
So why have it there at all? The short answer is statistics, filtering and the like. Currently all requests appear to originate locally but that is obviously not the true state of affairs. Requests come from all over the globe and any WordPress user using JetPack’s stats or similar plugins will keep an eye on a little world map, either for business purposes or just out of curiosity. Other applications may attempt geofiltering or just guessing at what language the user might prefer based on location (though I think it’s preferable to base that on the relevant header?)
I’m going to leave it out for now simply because I’m curious to see what Jetpack makes of all these local requests.
EDIT: After a week of no X-Forwarded-for I can say with certainty that at least JetPack does not rely on the header for information on where requests are coming from. If your statistics relies on logs rather than live scripts, though, it’s probably a worthwhile addition. The whole thing does make me question the utility of JetPack Stats to me, though, as I see nothing on the stats page that I could not derive from a log parser.
EDIT 2: I finally found a use case for X-Forwarded-for (I think). WordPress notes the originating ip address for comments in the comments queue awaiting moderation. In my case all comments have the same local ip address, that of the proxy. It’s weirdly graitifying because the idea that it – the lack of an accurate originating IP address – wouldn’t show up anywhere was slightly annoying to me.
Give me the baton, quick!!! flickr photo by Jun-Ely Fernan Gayosa shared under a Creative Commons (CC BY-SA 2.0) license

